
–ö–∞–∫ –±–æ–ª—å—à–∏–µ —è–∑—ã–∫–æ–≤—ã–µ –º–æ–¥–µ–ª–∏ –ø–æ–º–æ–≥–∞—é—Ç –≤ –ø–æ—Å—Ç—Ä–æ–µ–Ω–∏–∏ –æ–ø–µ—Ä–µ–∂–∞—é—â–∏—Ö –∏–Ω–¥–∏–∫–∞—Ç–æ—Ä–æ–≤ –º–∞–∫—Ä–æ—ç–∫–æ–Ω–æ–º–∏—á–µ—Å–∫–∏—Ö –ø–æ–∫–∞–∑–∞—Ç–µ–ª–µ–π –≠–∫–æ–Ω–æ–º–∏—á–µ—Å–∫–∏–µ –∞–≥–µ–Ω—Ç—ã –ø—Ä–∏–Ω–∏–º–∞—é—Ç —Ä–µ—à–µ–Ω–∏—è –Ω–µ —Ç–æ–ª—å–∫–æ –ø–æ–¥ –≤–ª–∏—è–Ω–∏–µ–º –æ—Ñ–∏—Ü–∏–∞–ª—å–Ω–æ–π —Å—Ç–∞—Ç–∏—Å—Ç–∏–∫–∏, –Ω–æ –∏ –ø–æ–¥ –≤–æ–∑–¥–µ–π—Å—Ç–≤–∏–µ–º –Ω–æ–≤–æ—Å—Ç–Ω–æ–≥–æ —Ñ–æ–Ω–∞, –∫–æ—Ç–æ—Ä—ã–π —Ñ–æ—Ä–º–∏—Ä—É–µ—Ç –æ–∂–∏–¥–∞–Ω–∏—è –æ—Ç–Ω–æ—Å–∏—Ç–µ–ª—å–Ω–æ –ø–µ—Ä—Å–ø–µ–∫—Ç–∏–≤ —Ä–∞–∑–≤–∏—Ç–∏—è –∏ –±—É–¥—É—â–∏—Ö –º–µ—Ä –ø–æ–ª–∏—Ç–∏–∫–∏. –≠—Ç–∏ —ç—Ñ—Ñ–µ–∫—Ç—ã –æ–ø–æ—Å—Ä–µ–¥–æ–≤–∞–Ω–Ω–æ –≤–ª–∏—è—é—Ç –Ω–∞ —Ä–µ–∞–ª—å–Ω—ã–π —Å–µ–∫—Ç–æ—Ä: —á–µ—Ä–µ–∑ –æ—Ç—Å—Ä–æ—á–∫—É –∏–Ω–≤–µ—Å—Ç–∏—Ü–∏–æ–Ω–Ω—ã—Ö —Ä–µ—à–µ–Ω–∏–π —Ñ–∏—Ä–º–∞–º–∏, –∏–∑–º–µ–Ω–µ–Ω–∏–µ —Å–∫–ª–æ–Ω–Ω–æ—Å—Ç–∏ –∫ —Å–±–µ—Ä–µ–∂–µ–Ω–∏—é –¥–æ–º–æ—Ö–æ–∑—è–π—Å—Ç–≤–∞–º–∏, –∫–æ—Ä—Ä–µ–∫—Ç–∏—Ä–æ–≤–∫—É –∏–Ω—Ñ–ª—è—Ü–∏–æ–Ω–Ω—ã—Ö –æ–∂–∏–¥–∞–Ω–∏–π. –ú–∏—Ö–∞–∏–ª –ê–Ω–∏–∫—É—Ç–∏–Ω, –Ω–∞—É—á–Ω—ã–π —Å–æ—Ç—Ä—É–¥–Ω–∏–∫ –ª–∞–±–æ—Ä–∞—Ç–æ—Ä–∏–∏ –æ—Ç—Ä–∞—Å–ª–µ–≤—ã—Ö —Ä—ã–Ω–∫–æ–≤ –∏ –∏–Ω—Ñ—Ä–∞—Å—Ç—Ä—É–∫—Ç—É—Ä—ã –ò–Ω—Å—Ç–∏—Ç—É—Ç–∞ –ì–∞–π–¥–∞—Ä–∞, —Ä–∞—Å—Å–∫–∞–∑–∞–ª –æ–± –∏—Å—Å–ª–µ–¥–æ–≤–∞–Ω–∏–∏ –ª–∞–±–æ—Ä–∞—Ç–æ—Ä–∏–∏, –≤ –∫–æ—Ç–æ—Ä–æ–º —ç–∫—Å–ø–µ—Ä—Ç—ã –ø–æ—Å—Ç—Ä–æ–∏–ª–∏ –∏–Ω–¥–∏–∫–∞—Ç–æ—Ä—ã –Ω–∞ –æ—Å–Ω–æ–≤–µ –∞–Ω–∞–ª–∏–∑–∞ –Ω–æ–≤–æ—Å—Ç–µ–π –¥–ª—è —Ä–æ—Å—Å–∏–π—Å–∫–æ–π —ç–∫–æ–Ω–æ–º–∏–∫–∏ —Å –ø–æ–º–æ—â—å—é –±–æ–ª—å—à–∏—Ö —è–∑—ã–∫–æ–≤—ã—Ö –º–æ–¥–µ–ª–µ–π (LLM) –∏ RAG-–∞—Ä—Ö–∏—Ç–µ–∫—Ç—É—Ä—ã.
–≠–≤–æ–ª—é—Ü–∏—è –ø–æ–¥—Ö–æ–¥–æ–≤ –∫ –∞–Ω–∞–ª–∏–∑—É –Ω–æ–≤–æ—Å—Ç–µ–π.
Первый этап словарный: текст считали позитивным или негативным по подсчету тональности слов. При этом методе контекст и нюансы смысла оставались за скобками, но уже давал мощные инструменты. Например, индекс экономической неопределенности (EPU), рассчитывался на основе частоты употребления местной прессой сочетания слов индикаторов (таких как «экономика», «неопределенность» и «политика»), уже зарекомендовал себя как важный фактор экономической динамики при моделировании ВВП и инвестиций.
–í—Ç–æ—Ä–æ–π —ç—Ç–∞–ø —Å–≤—è–∑–∞–Ω —Å –∞—Ä—Ö–∏—Ç–µ–∫—Ç—É—Ä–æ–π —Ç—Ä–∞–Ω—Å—Ñ–æ—Ä–º–µ—Ä–æ–≤, –∫–æ—Ç–æ—Ä–∞—è –Ω–∞—É—á–∏–ª–∞—Å—å –ø–æ–Ω–∏–º–∞—Ç—å —Å–µ–º–∞–Ω—Ç–∏–∫—É —Å–ª–æ–≤ –∏ –æ–ø–µ—Ä–∏—Ä–æ–≤–∞—Ç—å –∫–æ–Ω—Ç–µ–∫—Å—Ç–æ–º. –í 2018 –≥–æ–¥—É –ø–æ—è–≤–∏–ª—Å—è BERT, –∞ –∑–∞—Ç–µ–º –∏ —Å–ø–µ—Ü–∏–∞–ª–∏–∑–∏—Ä–æ–≤–∞–Ω–Ω—ã–µ –º–æ–¥–µ–ª–∏, —Ç–∞–∫–∏–µ –∫–∞–∫ FinBERT (2019), –¥–æ–æ–±—É—á–µ–Ω–Ω–∞—è –Ω–∞ —Ñ–∏–Ω–∞–Ω—Å–æ–≤—ã—Ö —Ç–µ–∫—Å—Ç–∞—Ö. –ò—Å—Å–ª–µ–¥–æ–≤–∞–Ω–∏—è –ø–æ–∫–∞–∑–∞–ª–∏, —á—Ç–æ –ø–æ—Å—Ç—Ä–æ–µ–Ω–Ω—ã–µ –Ω–∞ –µ—ë –æ—Å–Ω–æ–≤–µ –∏–Ω–¥–µ–∫—Å—ã —Ç–æ–Ω–∞–ª—å–Ω–æ—Å—Ç–∏ –ª—É—á—à–µ –æ–±—ä—è—Å–Ω—è—é—Ç –∫—Ä–∞—Ç–∫–æ—Å—Ä–æ—á–Ω—É—é —Ä–µ–∞–∫—Ü–∏—é —Ñ–æ–Ω–¥–æ–≤–æ–≥–æ —Ä—ã–Ω–∫–∞, –≤–∫–ª—é—á–∞—è –∞–Ω–æ–º–∞–ª—å–Ω—É—é –¥–æ—Ö–æ–¥–Ω–æ—Å—Ç—å –≤–æ–∫—Ä—É–≥ –≤—ã—Ö–æ–¥–∞ –Ω–æ–≤–æ—Å—Ç–µ–π –∏ –æ—Ç—á—ë—Ç–Ω–æ—Å—Ç–∏, –ø–æ —Å—Ä–∞–≤–Ω–µ–Ω–∏—é —Å —Ç—Ä–∞–¥–∏—Ü–∏–æ–Ω–Ω—ã–º–∏ –º–µ—Ç–æ–¥–∞–º–∏.
Третий этап – эпоха агентов и систем с дополненной генерацией (RAG). Ключевым прорывом стали модели с «цепочкой рассуждений» (chain‑of‑thought), которые перед ответом обдумывали решение. Например OpenAI GPT‑o1 (2024), и архитектура RAG, позволяющая LLM динамически извлекать актуальную информацию из внешних баз – новостных лент, пресс-релизов центрального банка, биржевых сводок. Современные исследования подтверждают, что построение новостных индексов на основе LLM с рассуждением и RAG полезно для прогнозирования. В работе Zijie Zhao и Roy E. Welsch портфель, сформированный на основе стратегии покупки акций с положительным сентиментом и продажи с негативным, обеспечил доходность выше S&P 500 в бычьем рынке на 4,8% и сократил убытки примерно в 5 раз в медвежьем.
–û—Ç–¥–µ–ª—å–Ω—ã–π –∏–Ω—Ç–µ—Ä–µ—Å –ø—Ä–µ–¥—Å—Ç–∞–≤–ª—è–µ—Ç –ø–µ—Ä–∏–æ–¥ –ø–æ—Å–ª–µ 2022 –≥–æ–¥–∞, —Å–æ–ø—Ä–æ–≤–æ–∂–¥–∞–≤—à–∏–π—Å—è —Å—Ç—Ä—É–∫—Ç—É—Ä–Ω—ã–º–∏ –∏–∑–º–µ–Ω–µ–Ω–∏—è–º–∏ –Ω–µ —Ç–æ–ª—å–∫–æ –≤ —ç–∫–æ–Ω–æ–º–∏–∫–µ, –Ω–æ –∏ –≤ –∏–Ω—Ñ–æ—Ä–º–∞—Ü–∏–æ–Ω–Ω–æ–º —Ñ–æ–Ω–µ.
–í —É—Å–ª–æ–≤–∏—è—Ö –∏–∑–º–µ–Ω–µ–Ω–∏—è —Ç–µ—Ä–º–∏–Ω–æ–ª–æ–≥–∏–∏ –º–µ—Ç–æ–¥—ã, –æ—Å–Ω–æ–≤–∞–Ω–Ω—ã–µ –Ω–∞ –∫–ª—é—á–µ–≤—ã—Ö —Å–ª–æ–≤–∞—Ö, –æ–∫–∞–∑—ã–≤–∞—é—Ç—Å—è –º–µ–Ω–µ–µ —É—Å—Ç–æ–π—á–∏–≤—ã–º–∏, —Ç–æ–≥–¥–∞ –∫–∞–∫ —è–∑—ã–∫–æ–≤—ã–µ –º–æ–¥–µ–ª–∏ –ª—É—á—à–µ –∞–¥–∞–ø—Ç–∏—Ä—É—é—Ç—Å—è –±–ª–∞–≥–æ–¥–∞—Ä—è —Å–µ–º–∞–Ω—Ç–∏—á–µ—Å–∫–æ–º—É –∞–Ω–∞–ª–∏–∑—É —Ç–µ–∫—Å—Ç–∞.
–ö–∞–∫ –ª–∞–±–æ—Ä–∞—Ç–æ—Ä–∏—è –æ—Ç—Ä–∞—Å–ª–µ–≤—ã—Ö —Ä—ã–Ω–∫–æ–≤ –∏ –∏–Ω—Ñ—Ä–∞—Å—Ç—Ä—É–∫—Ç—É—Ä—ã —Å—Ç—Ä–æ–∏—Ç –Ω–æ–≤–æ—Å—Ç–Ω—ã–µ –∏–Ω–¥–µ–∫—Å—ã?
–ü–æ–¥—Ö–æ–¥ –ò–Ω—Å—Ç–∏—Ç—É—Ç–∞ –ì–∞–π–¥–∞—Ä–∞ –æ–±—ä–µ–¥–∏–Ω—è–µ—Ç —à–∏—Ä–æ–∫—É—é –±–∞–∑—É –∏—Å—Ç–æ—á–Ω–∏–∫–æ–≤ (240 —Ç—ã—Å. –Ω–æ–≤–æ—Å—Ç–µ–π —Å 2015 –≥–æ–¥–∞ –∏–∑ –¢–ê–°–°, –Ý–ë–ö, –ò–Ω—Ç–µ—Ä—Ñ–∞–∫—Å–∞ –∏ –ø—Ä–µ—Å—Å-—Ä–µ–ª–∏–∑–æ–≤ –¶–ë) —Å —è–∑—ã–∫–æ–≤–æ–π –º–æ–¥–µ–ª—å—é DeepSeek, –∏—Å–ø–æ–ª—å–∑—É—é—â–µ–π –º–µ—Ö–∞–Ω–∏–∑–º —Ä–∞—Å—Å—É–∂–¥–µ–Ω–∏—è –∏ —Å–∏—Å—Ç–µ–º—É –¥–æ–ø–æ–ª–Ω–µ–Ω–Ω–æ–≥–æ –ø–æ–∏—Å–∫–∞ (RAG).
–û—Ç–±–æ—Ä –Ω–æ–≤–æ—Å—Ç–µ–π. –ü—Ä–∏–º–µ–Ω—è–µ—Ç—Å—è –º–µ—Ö–∞–Ω–∏–∑–º —Ä–∞–Ω–∂–∏—Ä–æ–≤–∞–Ω–∏—è, –Ω–∞—Å—Ç—Ä–æ–µ–Ω–Ω—ã–π –Ω–∞ —Ü–µ–ª–µ–≤—ã–µ –º–∞–∫—Ä–æ–ø–æ–∫–∞–∑–∞—Ç–µ–ª–∏: –ø—Ä–æ–º—ã—à–ª–µ–Ω–Ω–æ–µ –ø—Ä–æ–∏–∑–≤–æ–¥—Å—Ç–≤–æ, –∏–Ω—Ñ–ª—è—Ü–∏—è, –í–í–ü, —Ä–µ–∞–ª—å–Ω–∞—è –∑–∞—Ä–ø–ª–∞—Ç–∞. –°–∏—Å—Ç–µ–º–∞ –æ—Ç–±–∏—Ä–∞–µ—Ç —Ç–æ–ª—å–∫–æ —Ç–µ –Ω–æ–≤–æ—Å—Ç–∏, –∫–æ—Ç–æ—Ä—ã–µ –¥–µ–π—Å—Ç–≤–∏—Ç–µ–ª—å–Ω–æ —Ä–µ–ª–µ–≤–∞–Ω—Ç–Ω—ã –¥–ª—è –æ—Ü–µ–Ω–∫–∏ –≤–ª–∏—è–Ω–∏—è –Ω–∞ –¥–∞–Ω–Ω—ã–π –ø–æ–∫–∞–∑–∞—Ç–µ–ª—å.
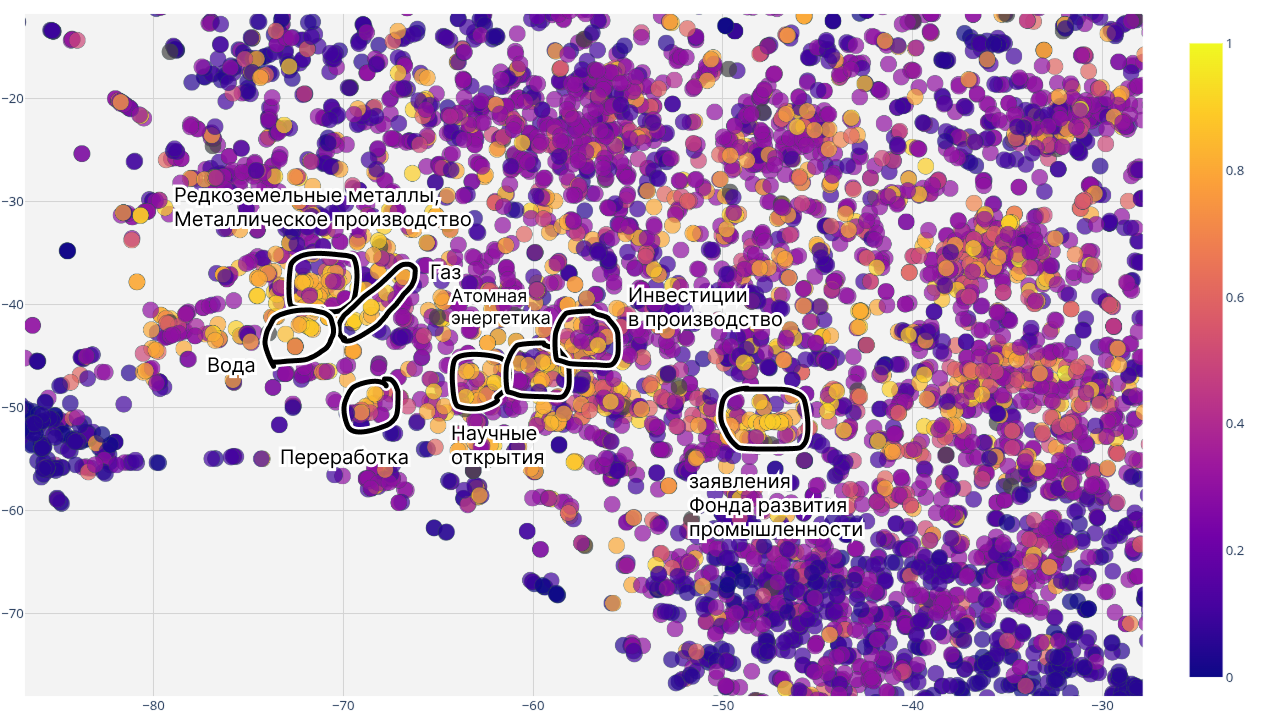
–Ý–∏—Å: –∫–ª–∞—Å—Ç–µ—Ä—ã —Ä–µ–ª–µ–≤–∞–Ω—Ç–Ω—ã—Ö –Ω–æ–≤–æ—Å—Ç–µ–π –ø–æ —Ç–µ–º–µ ‚Äú—Ö–∏–º–∏—á–µ—Å–∫–æ–µ –ø—Ä–æ–∏–∑–≤–æ–¥—Å—Ç–≤–æ‚Äù
–Ý–∞–∑–º–µ—Ç–∫–∞ –∫–æ–Ω—Ç–µ–∫—Å—Ç–∞. –î–ª—è –∫–∞–∂–¥–æ–π –Ω–æ–≤–æ—Å—Ç–∏ —Å–∏—Å—Ç–µ–º–∞ –Ω–∞—Ö–æ–¥–∏—Ç —Å–µ–º–∞–Ω—Ç–∏—á–µ—Å–∫–∏ –∏ –ª–µ–∫—Å–∏—á–µ—Å–∫–∏ –±–ª–∏–∑–∫–∏–µ –æ—Ç—Ä—ã–≤–∫–∏ ‚Äì –ø—É–±–ª–∏–∫–∞—Ü–∏–∏ –Ω–∞ —Ç—É –∂–µ —Ç–µ–º—É –∏–ª–∏ —Å–≤—è–∑–∞–Ω–Ω—ã–µ –ø—Ä–µ—Å—Å-—Ä–µ–ª–∏–∑—ã –¶–ë. –ì–∏–±—Ä–∏–¥–Ω—ã–π –ø–æ–∏—Å–∫ —Å–æ—á–µ—Ç–∞–µ—Ç —Å–º—ã—Å–ª–æ–≤—É—é –±–ª–∏–∑–æ—Å—Ç—å –∏ —Ç–æ—á–Ω—ã–µ —Å–æ–≤–ø–∞–¥–µ–Ω–∏—è —Ç–µ—Ä–º–∏–Ω–æ–≤, —á—Ç–æ –ø–æ–ª–µ–∑–Ω–æ –¥–ª—è –∏–¥–µ–Ω—Ç–∏—Ñ–∏–∫–∞—Ü–∏–∏ —Ç–∏–∫–µ—Ä–æ–≤ –∫–æ–º–ø–∞–Ω–∏–π, –Ω–∞–∑–≤–∞–Ω–∏–π –∞–∫—Ç–∏–≤–æ–≤ –∏ —Ç.–¥.
Оценка тональности. Модель получает новость, обогащенную контекстом, и оценивает тональность текста, а также степень своей уверенности. Полученные оценки агрегируются в новостной индекс: возможны варианты расчета – частота негативных новостей, отношение негативных ко всем выпущенным или средняя тональность за период.
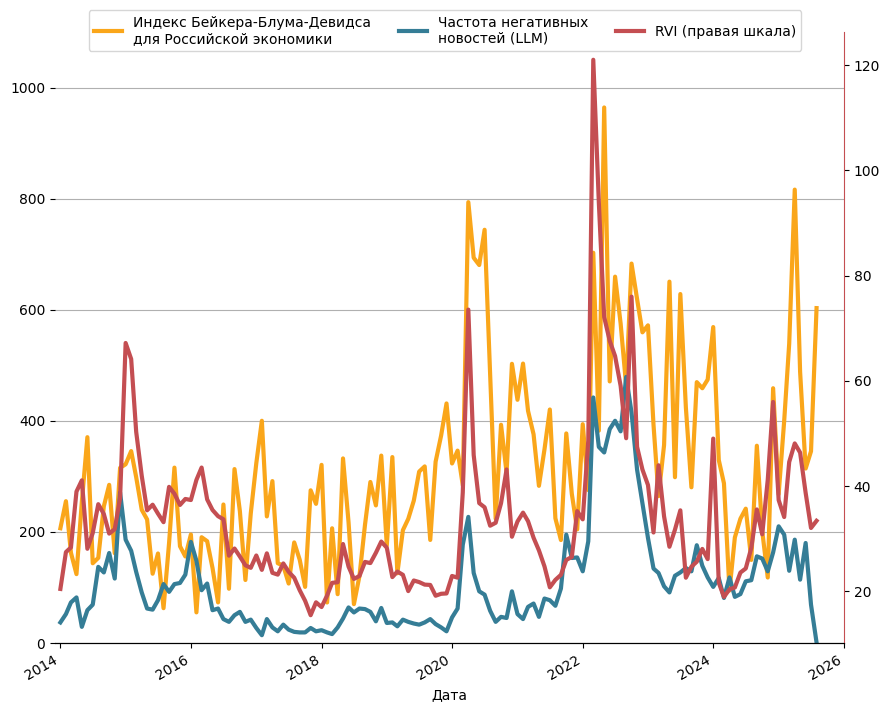
Лаборатория использует построенные индексы для прогнозирования отраслевых индексов промышленного производства. Наибольший эффект наблюдается для отраслей, которые до 2022 года в высокой степени зависели от внешней торговли и импортных поставок – прежде всего производства машин и оборудования, металлургической промышленности, а также производства резиновых и пластмассовых изделий. Для таких отраслей новостной поток относительно быстро отражает изменение внешних условий деятельности компаний: санкционные ограничения, разрывы логистических цепочек, пересмотр контрактов и доступность импорта. В результате новостной индекс содержит информацию о будущей динамике выпуска раньше, чем соответствующие изменения проявляются в официальной статистике.
Для отраслей с более длинным производственным циклом и высокой инерционностью выпуска – например, производство нефтепродуктов и химическое производство – даже значимые оперативные изменения внешней конъюнктуры и ценовых условий не всегда приводят к быстрому изменению выпуска из-за ограничений производственной инфраструктуры, долгосрочных контрактов и низкой краткосрочной эластичности предложения. В результате новостной фон оказывается менее полезным для краткосрочного прогнозирования.
–ü–µ—Ä—Å–ø–µ–∫—Ç–∏–≤—ã
–Ý–∞–∑–≤–∏—Ç–∏–µ –ò–ò –æ—Ç–∫—Ä—ã–≤–∞–µ—Ç –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç–∏ –¥–ª—è –∞–Ω–∞–ª–∏–∑–∞ —Å–ª–æ–∂–Ω—ã—Ö –Ω–µ—Å—Ç—Ä—É–∫—Ç—É—Ä–∏—Ä–æ–≤–∞–Ω–Ω—ã—Ö –¥–∞–Ω–Ω—ã—Ö. –°–ª–µ–¥—É—é—â–∏–π —à–∞–≥ ‚Äì –∞–≥–µ–Ω—Ç–Ω—ã–µ —Å–∏—Å—Ç–µ–º—ã, —Å–ø–æ—Å–æ–±–Ω—ã–µ —Å–∞–º–æ—Å—Ç–æ—è—Ç–µ–ª—å–Ω–æ –Ω–∞—Ö–æ–¥–∏—Ç—å —Ä–µ–ª–µ–≤–∞–Ω—Ç–Ω—É—é –∏–Ω—Ñ–æ—Ä–º–∞—Ü–∏—é –∏ –ø—Ä–æ–≤–æ–¥–∏—Ç—å —Ä–∞—Å—á–µ—Ç—ã –¥–ª—è –æ—Ü–µ–Ω–∫–∏ —ç–∫–æ–Ω–æ–º–∏—á–µ—Å–∫–æ–≥–æ —ç—Ñ—Ñ–µ–∫—Ç–∞ –Ω–æ–≤–æ—Å—Ç–Ω–æ–≥–æ —Ñ–æ–Ω–∞. –ü–µ—Ä—Å–ø–µ–∫—Ç–∏–≤–Ω–æ —Ç–∞–∫–∂–µ –º–æ–¥–µ–ª–∏—Ä–æ–≤–∞–Ω–∏–µ –≥—Ä–∞—Ñ–æ–≤ –Ω–æ–≤–æ—Å—Ç–µ–π: –∏–∑—É—á–µ–Ω–∏–µ —Å–≤—è–∑–µ–π –º–µ–∂–¥—É —Å–æ–æ–±—â–µ–Ω–∏—è–º–∏, –¥–∏–Ω–∞–º–∏–∫–∏ –Ω–∞–∫–æ–ø–ª–µ–Ω–Ω–æ–π —Ç–æ–Ω–∞–ª—å–Ω–æ—Å—Ç–∏ –≤ –∑–∞–≤–∏—Å–∏–º–æ—Å—Ç–∏ –æ—Ç –∫–æ–Ω—Ç–µ–∫—Å—Ç–∞ –∏ —Ç—Ä–∞–Ω—Å—Ñ–æ—Ä–º–∞—Ü–∏–∏ —ç–∫–æ–Ω–æ–º–∏—á–µ—Å–∫–∏—Ö –æ–∂–∏–¥–∞–Ω–∏–π –ø–æ–¥ –≤–ª–∏—è–Ω–∏–µ–º –∫–æ–Ω–∫—Ä–µ—Ç–Ω—ã—Ö —Å–æ–±—ã—Ç–∏–π.